How to Simulate the Number of Losses on a Portfolio?
Simulations
Frequency
Trend
Published
November 15, 2023
In a previous post we simulated a portfolio of insurance policies. Today, we simulate its loss count.
We will need the portfolio data frame policy_df that we generated back then. With the below, we re-run that code. The code below will regenerate that data with the actuarialRecipes package:
We can be interested in either bulk simulations of the total number of losses over a period of time, or in how many losses have been generated by each policy of the portfolio. We will look at both situations in this post.
Choice of Frequency Distribution
I will assume that the loss count for each policy is independent, Poisson distributed. This implicitly assumes that the timing of losses is independent1. In other words, the fact that a policy had a loss at a given time does not change the distribution of future losses (for this policy and for the rest of the portfolio). This intuitively makes sense and is mostly in line with real data 2.
I will assume that the frequency distribution for exposures written on January 1, 2010 is 5.87%. This means that one exposure written at this date will inccur on average 0.0587 losses in a year. We further assume that the frequency decreases at an annual rate of 1%.
initial_freq <-0.0587freq_trend <--1/100
Bulk Simulation
In a bulk simulation we simulate the number of losses for a cohort of exposures over period of time. In this case, we will look at the number of losses generated by the policies written in each year.
Calculation of the Annual Loss Frequencies
The total claim count for a group of policy is Poisson distributed with frequency the sum of the frequencies of the individual policy exposures. This is because the claim counts of each exposure is Poisson and independent from one another. For simplicity, we assume that the frequency is the same for all exposure written in the same year. As a result, the claim count of any given policy year is proportional to the number of written exposures.
We therefore calculate the number of written exposure per year:
Now, we can calculate the frequency for exposures written in each annual cohort. The frequency needs to be trended from the January 1, 2010 to the average inception date of each cohort:
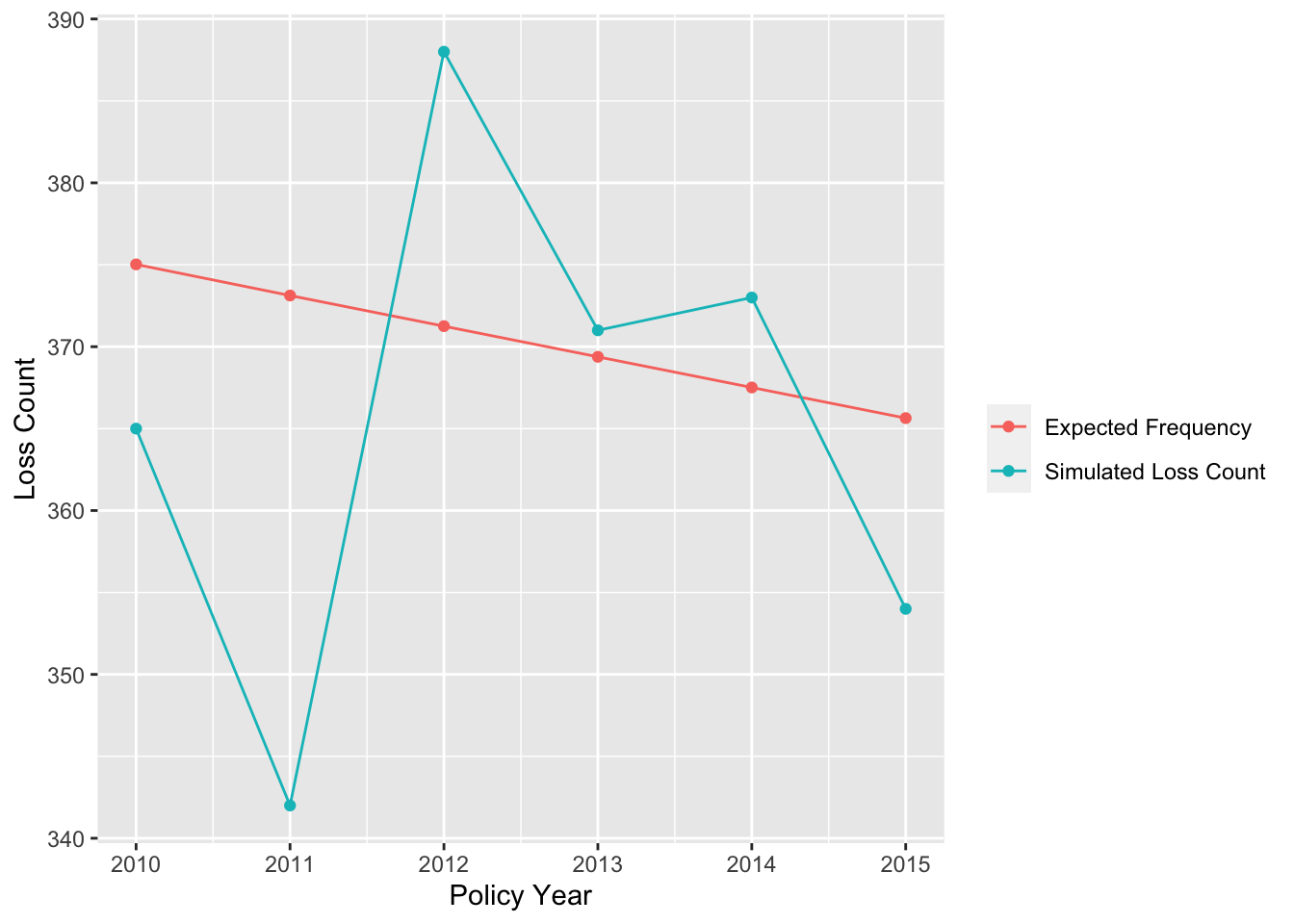
We can compare the expected frequency to the simulated total loss count:
Code
freq_df |>rename(`Expected Frequency`= exp_claim_count,`Simulated Loss Count`= loss_count) |>pivot_longer(c("Expected Frequency", "Simulated Loss Count")) |>ggplot(aes(PY, value, color = name)) +geom_line() +geom_point() +ylab("Loss Count") +xlab("Policy Year") +labs(color ="")
Comparing Expected Claim Frequency to Simulated Loss Count
Our simulated loss count is close to the expected frequency. However, the simulated number goes up and down around the expected frequency and we cannot discern a downward trend.
This is due to the natural variability of the Poisson distribution. We can show this by comparing the simulated loss count to the 90% confidence interval of the distribution:
qpois is the quantile function of the Poisson distribution.
PY
exp_claim_count
lower_bound
upper_bound
loss_count
2010
375.0235
343
407
365
2011
373.1236
342
405
342
2012
371.2528
340
403
388
2013
369.3821
338
401
371
2014
367.5116
336
399
373
2015
365.6417
334
397
354
Comparing Simulated Loss Count to Confidence Intervals
We can see from the table that all simulated loss counts fall within the 90% confidence interval, which helps us validate our results.
Policy-per-Policy Simulation
The previous simulation only tells us about the total number of losses generated in each cohort. However, it does not tell which policy or exposure generated which loss. This is limiting for some applications. For example, we may want to have the size of losses vary depending on exposure characteristics. In this case, we need to simulate a loss count per policy. We see how to do this in the rest of this post:
Calculate average frequency per Policy
First, we need to calculate the expected frequency of loss for each policy. We do this by trending the initial frequency from January 1, 2010 to the inception date of each policy:
rpois will simulate a Poisson random variable for each row in the policy_df data frame, with the corresponding frequency given by the frequency column.
Simulated Claim Count for the first Policy of Each Year
As the expected claim count is around 3% we expect most policies will have no claim.
Check results and compare
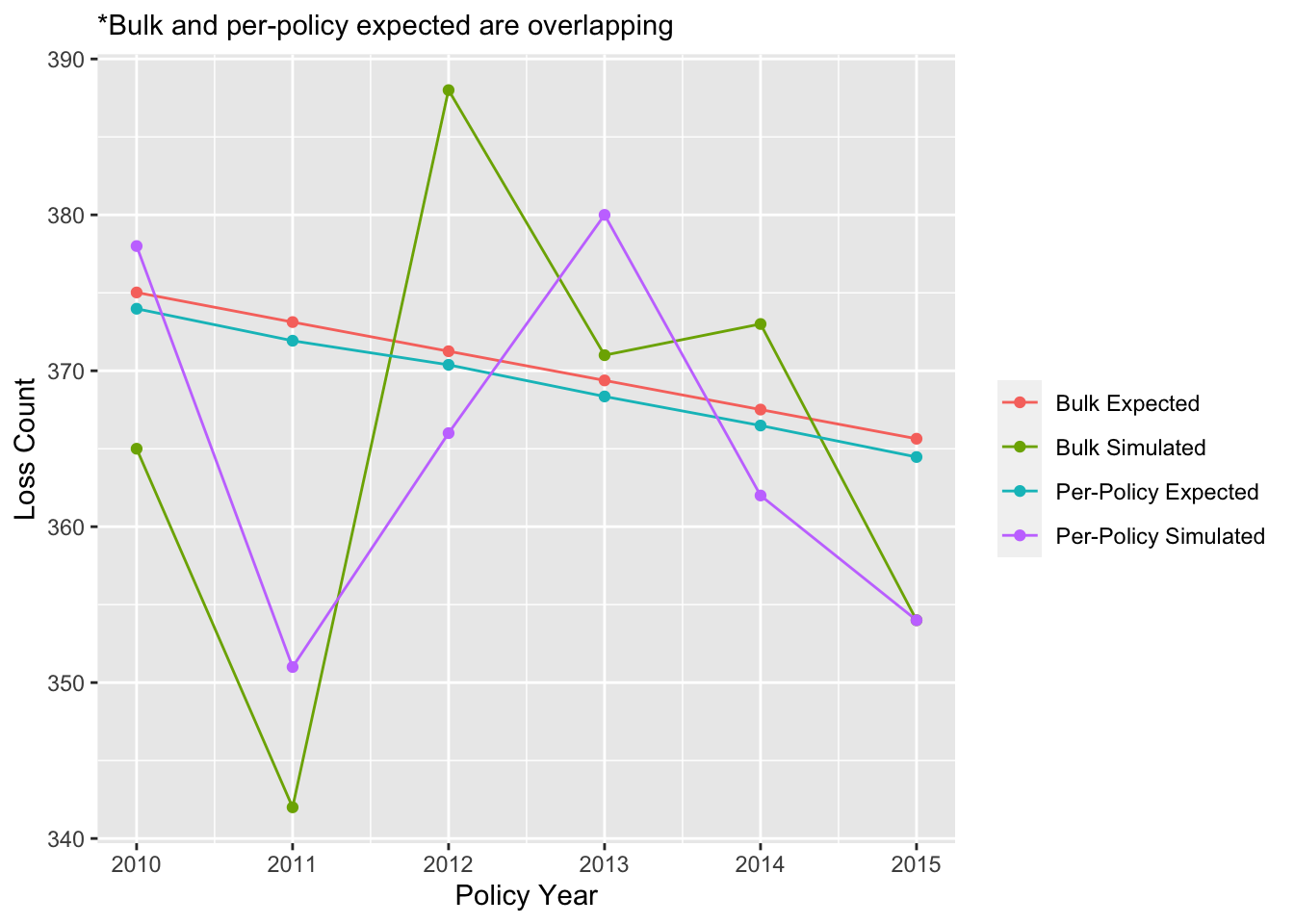
As a check, we compare these results to the bulk simulations above. We therefore aggregate the policy table to obtain annual expected frequencies and simulated claim counts:
Comparing Bulk Annual to Per-Policy Frequency Simulations
The bulk and the per-policy expected loss frequencies are very close but not exactly the same. This is because the policy durations are not exactly half a year as we assumed in the bulk simulation. In fact, the policy durations can be slightly shorter or longer depending on the inception date. On average, it is slightly shorter for the overall portfolio. This results in a lower expected claim count for the per-policy simulation than for the bulk simulation.
On the other hand, the simulated loss counts are different due to the natural volatility of the Poisson distribution. We can however verify that the per-policy simulated loss count is within the 90% confidence interval we derived for the bulk simulation.
The Function That Does it All
The simulate_loss_count function from the actuarialRecipes package reproduces the per-policy simulation:
The returned value loss_count is a vector with the number of losses for each policy in policy_df.
Conclusion
In summary, we have seen too approaches to simulate loss counts for a portfolio of policies: a bulk approach that simulates claim counts on annual cohorts of written policies, and a per-policy approach that simulates the claim count for individual policies. The latter approach is the most flexible, as it gives us the possibility to simulate a dataset of individual losses, with claim amount and occurrence date. We will explore this topic in a future post.
Footnotes
This is linked to the memory-free property of the exponential distribution. But this is a topic for another post.↩︎
Well, in many situations the loss distribution is slightly “over-dispersed” and one can adjust the Poisson distribution or use another one to reflect this. This is again a topic for another post. In most cases however, the Poisson distribution is just fine as a first approximation.↩︎