How to simulate a portfolio of insurance policies?
Simulations
Premium Trend
Rate Change
Published
November 7, 2023
Why is my first post on simulating insurance data? Well, the insurance industry is notorious for not easily sharing data. This means that the best way to study different methods is often to use synthetic data.
This post will go through the basics of simulating a portfolio of policies with R, with exposure and premium data. We will simulate data that response to changes due to exposure growth, premium trend and rate change, while making simplifying assumptions to keep things short. I’m planning to write follow-up articles that will look at ways to make the simulation more detailed.
However, this is a fairly technical post as we will need to use different libraries for data manipulation. Date manipulation is particularly tricky and we will need to be careful in writing code that produces the inception and exiration dates with expect.
About the Data
We will simulate the portfolio from Appendix A of the Werner & Modlin Study Note. Members of the CAS (Casualty Actuarial Society) may be familiar with it, since it’s on the syllabus of Exam 5 (Basic Ratemaking).
The data come from a fictitious portfolio of property damage liability covers from a personal automobile insurance in the United States. Each policy in this portfolio is semi-annual. I will assume that each policy only covers property damage liability, and only covers one unit of exposure (one automobile).
Libraries and Utility Functions
We will use the following packages from the tidyverse:
A very important package for manipulating data in data frames.
2
A set of functions to make working with date easier.
3
Provides a more readable alternative to for loops.
4
The most popular R plotting library
5
Useful functions for pretty printing numbers
The tidyverse, particularly dplyr, is the state of the art for data wrangling in R. If you are not already familiar with it, I strongly encourage you to invest some time in learning it. At a high-level, dplyr introduces very well designed functions that make data wrangling problem much easier to approach.R for Data Science provides an excellent introduction (See Chapter 4).
Policy Data
First, we have to simulate the policies. Let us state our assumptions:
We simulate a portfolio from 2010 to 2015.
In 2010 the insurer writes 12842 policies
Each year, the policy count grows by 0.5%
Policies are semi-annual
Policies are written uniformely in any given year
Number of Policies and Portfolio growth
To apply the trend, I will define a convenience function that extrapolate a value to future years, given an annual trend:
apply_trend <-function(value, from, to, trend) { trend_period <- to - from value * (1+ trend) ^ trend_period}
Let us use this function to calcule how many policies we have to simulate for each year.
A tibble is an improved version of base R data frame.
year
n_policies
2010
12842
2011
12906
2012
12971
2013
13036
2014
13101
2015
13166
You will notice that we store the generated data in a data frame. As a general rule we should alway try to store data in a data frame. This is because it is usually the cleanest and most practical way to store data.
Policy Ids and Inception Dates
Now that we have the number of policies written in each year, we have to simulate the policies, with their inception dates. We can achieve this by looping over each simulated year and generating a sequence of uniformely spread days in the given year. That uniform sequence of dates can be generated with this function:
# A uniformely spread list of `n` dates within year `y`seq_date_in_year <-function(y, n) { from <-first_day_of_year(y) to <-first_day_of_year(y +1)seq(from, to, length.out = n +1)[1:n]}
1
With the seq function we need this trick of asking for an extra data point to have a truly uniform sequency of dates within a given year.
seq_date_in_year needs two convenience functions to generate dates given a year:
We can know use seq_date_in_year to generate the inceptions dates of all policies in each of the simulated year. We also give each policy a unique policy id of the form policy_<year>_<n>, where <year> is the inception year of the policy and <n> means that the policy was the \(n^{\text{th}}\) written in that year.
A function to simulate the policies for one given year.
2
pmap_dfr loops through each row of annual_df and executes the function generate_one_year_policy_data for each year. Binds the returned data frames by row to return a single data frame.
Now we have to give an expiration date to each policy. Here we need to proceed carefully, because dates can be tricky. Since the policies are semi-annual, we a priori need to add 6 months to the inception date. However, adding 6 months to March 31st will cause problem because September 31st does not exist. We therefore need to use the %m+% function from the lubridate package which takes care of rolling back such imaginary dates to an existing date. Another thing we need to do is to substract one day so that the expiration date corresponds to the last day the policy is in force, instead of being the first day when the policy is not in force.
The below code adds the new expiration_date column with all the above in mind:
To keep things simple, I will assume tht each policy only covers one automobile (one unit of exposure). I will explore what happens when we deviate from this assumption in latter posts.
We will assume that the premium is $87 per unit of exposure (or equivalently per policy) on the first day of our simulation period: January 1st, 2010. This premium really represents an average premium per exposure, but we will wait for another post to look at how we can make more complex simulation that have premium vary with different risk characteristics.
Average premiums change over time in two ways:
By jumps. Typically, this happens after a rate change has been implemented.
Gradually. Typically, shifts in the mix of business and average insurance conditions happen continuously over time and result in a premium trend
We will simulate both rates changes and premium trend in our portfolio. For now we initialize the premium of each policy with the initial average premium:
We assume the same rate changes as in Werner & Modlin1. We assume the rate changes impacts only policies written on or after the effective date. This is generally what happens when a rate change is implemented.
The lubridate function dmy takes a string with a Month/Day/Year format and transforms it to a proper Date object.
effective_date
rate_change
2011-01-04
-5%
2012-01-07
10%
2013-01-10
5%
2014-01-07
-2%
2015-01-10
5%
2016-01-01
5%
Rates Changes over the Simulated Period
We now need to loop through each of these rate changes and increase the premium by the corresponding percent change for all policies written on or after the effective date.
We further modify the premium to reflect a 2% premium trend. This trend captures the impact on premium of gradual shifts in risk profiles of insureds and the insurance conditions of the policies.
We need to to improve our previous apply_trend function to be able to apply a trend between any two dates:
apply_trend <-function(value, from, to, trend) { from <-if (is.Date(from)) from elsefirst_day_of_year(from) to <-if (is.Date(to)) to elsefirst_day_of_year(to) trend_period <- (from %--% to) /years(1) value * (1+ trend) ^ trend_period}
1
If from and to are years, tranforms them to dates
2
This calculate the duration in years between the from date and the to date. %--% is a lubridate operator that calculates a time interval between two dates. years(1) creates a period of one year. Dividing an interval by a period calculates the interval length with the period as a unit of measurement.
We now use this modified version of apply_trend to modify the premium column with the trend.
We have reached the end of our simulation. It is time to verify our results. A very good first thing to do is to calculate aggregate value over policy year to verify that the aggregate and average values make sense:
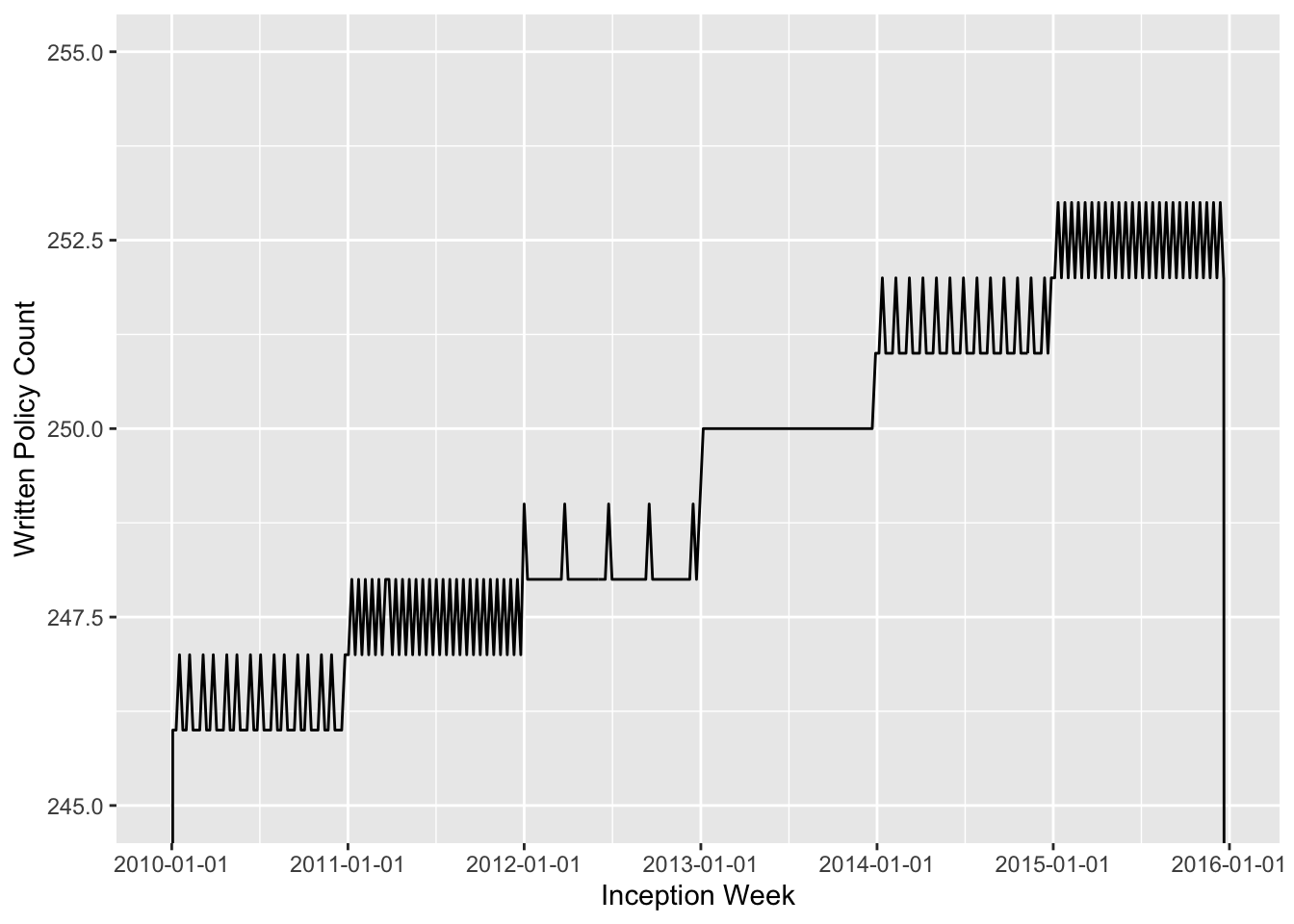
From this plot we can validate that the policy count is evenly spread throughout any given year, and that the policy count grows at a 0.5% rate between years.
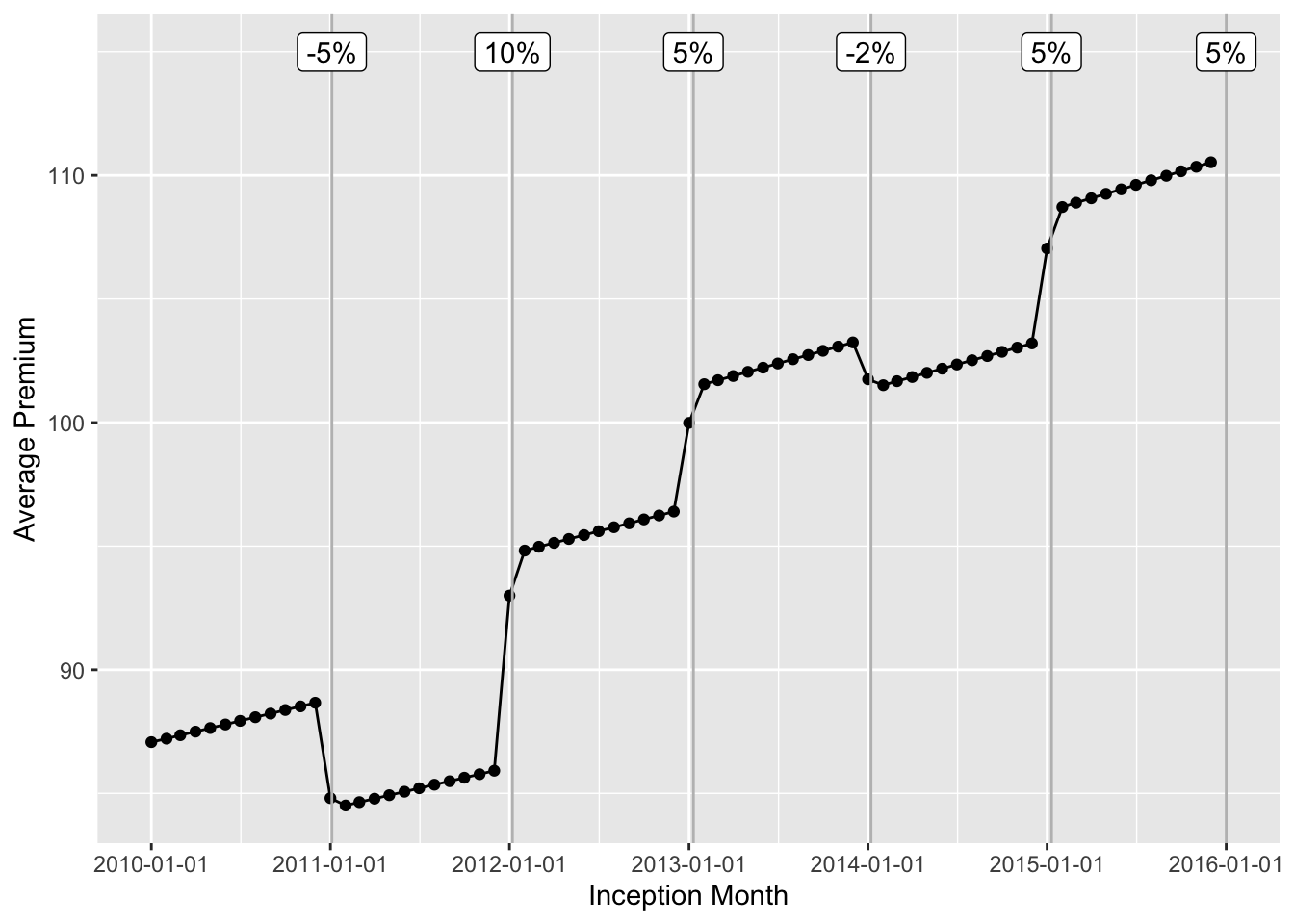
Now lets look at the average monthly premium to validate the rate changes and premium trend. We also overlay the timing of the rate changes to the plot.
We can clearly identify a constant premium trend and jumps around the effective date of the rate changes.
The Function That Does it All
You can use the function simulate_portfolio from the actuarialRecipes package to resimulate the same portfolio without having to through all of the above steps.
The package is not on CRAN and you will need to install it from GitHub through:
This was a fairly long post and quite technical. But we now have a way to simulate portfolios of policies. We will use this in the next posts to do actually perform actuarial analysis.